多智能体对立作为决议计划AI中重要的部分,也是强化学习范畴的难题之一。为丰厚多智能体对立环境,OpenDILab(开源决议计划智能渠道)开源了一款多智能体对立竞技游戏环境——Go-Bigger。一起,Go-Bigger还可作为强化学习环境帮忙多智能体决议计划AI研讨。
与风行全球的agar.io、球球大作战等游戏相似,在Go-Bigger中,玩家(AI)操控地图中的一个或多个圆形球,经过吃食物球和其他比玩家球小的单位来尽可能取得更多分量,并需避免被更大的球吃掉。每个玩家开端仅有一个球,当球到达足够大时,玩家可使其割裂、吐孢子或交融,和伙伴完美合作来输出博弈战略,并经过AI技能来操控智能体由小到大地进化,凭仗对团队中多智能体的战略操控来吃掉尽可能多的敌人,然后让己方变得更强壮并取得终究成功。

四类小球,应战不同决议计划途径
Go-Bigger选用Free For All(FFA)方法来进行竞赛。竞赛开端时,每个玩家仅有一个初始球。经过移动该球,玩家可吃掉地图上的其他单位来获取更大的分量。每个部队都需和其他全部部队进行对立,每局竞赛继续十分钟。竞赛完毕后,以每个部队终究取得的分量来进行排名。
在一局竞赛中共有兼顾球、孢子球、食物球、荆棘球四类球。兼顾球是玩家在游戏中操控移动或许技能开释的球,能够经过掩盖其他球的中心点来吃掉比自己小的球;孢子球由玩家的兼顾球发射发生,会留在地图上且可被其他玩家吃掉;食物球是游戏中的中立资源,其数量会坚持动态平衡。如玩家的兼顾球吃了一个食物球,食物球的分量将被传递到兼顾球;荆棘球也是游戏中的中立资源,其尺度更大、数量更少。如玩家的兼顾球吃了一个荆棘球,荆棘球的巨细将被传递到兼顾球,一起兼顾球会爆破并割裂成多个兼顾。此外,荆棘球可经过吃掉孢子球而被玩家移动。

兼顾球
团队紧密合作,完结合理分量传递
在Go-Bigger中,团队内部的合作和外部的竞技关于终究的成果至关重要。因而,Go-Bigger规划了一系列的规矩来进步团队所能带来的收益。因为玩家的兼顾球分量越小,移动速度越快,更多的兼顾能够确保快速发育,可是会面临被其他玩家吃掉的风险。一起,冷却期的存在使得玩家无法靠本身脱节这样的风险。因而,同一部队中不同玩家的合作尤为要害。
为便于团队内玩家的合作,Go-Bigger设置了玩家无法被同部队彻底吃掉的规矩。Go-Bigger还设置了单个兼顾球的分量上限和分量衰减,使得单一兼顾球无法坚持过大分量,迫使其割裂以削减分量丢失。在游戏后期,团队内部的分量传递会显得至关重要,合理的分量传递能够确保团队在与其他部队对立时取得更大的优势。
支撑RL环境,供给三种交互方法
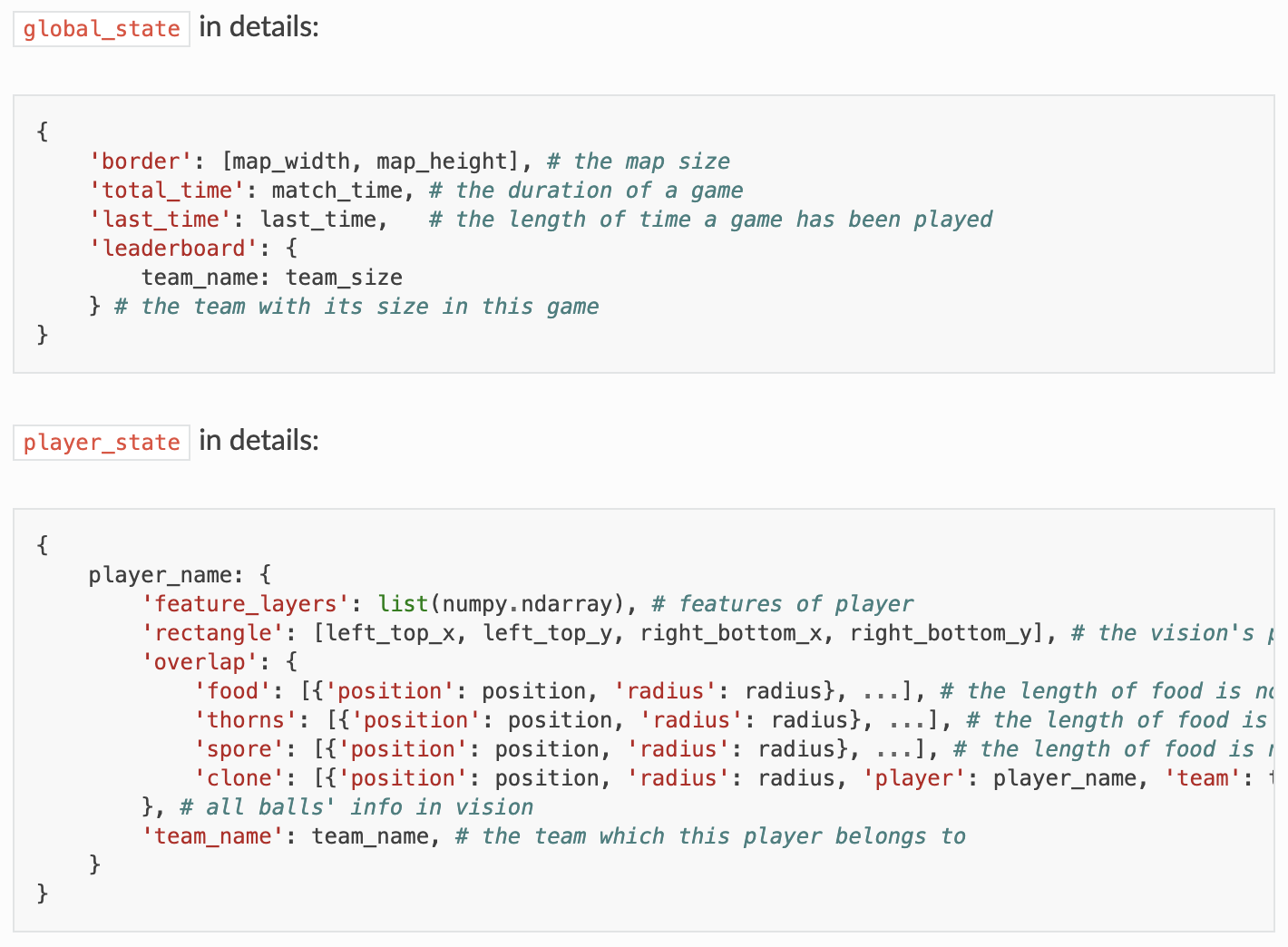
此外,为协助用户在强化学习范畴的多智能体战略学习,Go-Bigger也供给了契合gym.Env规范的接口供其运用。在一局游戏中,Go-Bigger默认设置含有20个状况帧和5个动作帧。每个状况帧都会对当时地图内全部单位进行仿真和状况处理,而动作帧会在此根底上,附加对单位的动作操控,即改动单位的速度、方向等特点,或使单位启用割裂、发射或中止等技能。
为了更方便地对环境进行探究,Go-Bigger还供给了必要的可视化东西。在与环境进行交互的时分,能够直接保存本局包含大局视角及各个玩家视角的录像。此外,Go-Bigger供给了单人大局视界、双人大局视界、单人部分视界三种人机交互方法,使得用户能够快速了解环境规矩。
三步走,快速建立强化学习baseline
算法baseline的意图是验证某个问题环境运用强化学习算法的开始作用,对各个环节的信息做简略整理和剖析,了解之后便可轻松上手竞赛,在环境、算法、算力上逐渐添加杂乱度,规划迭代作用更强的智能体。
Go-Bigger环境的强化学习算法baseline首要分为环境减肥、根底算法挑选、定制练习流程三部分。其间,环境减肥行将原始游戏环境简化成适用于强化学习的规范环境格局;根底算法挑选指依据环境的根本信息挑选合理的根底RL算法;定制练习流程指依据环境的特别特征定制练习流程。
- 环境减肥
- 人类视角的Go-Bigger(上)S. 翻译成游戏引擎中的结构化信息(下):

这些人了解起来很简略的数据表明,对计算机和神经网络却十分不友好,因而需求专门对这些信息做必定的加工,并依据强化学习的特性设置成规范的强化学习环境调查空间。
- 特征工程:
- 原始的游戏数据需求表达游戏内容,其数值规模动摇便会较大(比方从几十到几万的球体巨细),直接将这样的信息输入给神经网络会形成练习的不稳定,所以需求依据信息的具体特征进行必定的处理(比方归一化,离散化,取对数坐标等等)。
- 关于类别信息等特征,不能直接用原始的数值作为输入,常见的做法是将这样的信息进行独热编码,映射到一个两两之间间隔持平的表明空间。
![]()
- 关于坐标等信息,运用肯定坐标会带来一些映射联络的不一致问题,相对坐标一般是更好的处理方法。
- 从RGB图画到特征图画层

直接将原始的RGB 2D图画信息输入神经网络,虽然成果尚可,但需求更多的数据、更长的练习时刻,以及更杂乱的练习技巧。更为简明并有用的方法是进行“升维”,行将耦合在一起的图画信息离解成多个别离的特征图画层。终究依据游戏内容界说出具体的特征图画层,并区别各个玩家的部分视界,拼接后构成整体的特征图画层。下图为一玩家视界中食物球的特征图画层:

- 可变维度
Go-Bigger环境中存在许多可变维度的当地,为了简化,baseline环境中强行切断了单位数量,用一致的方法来躲避可变维度问题。
- 规划动作空间
Go-Bigger关于人类来说操作起来十分简略,包含上下左右QWE,这些根本的按键组合起来便能够诞生出许多风趣的操作,如十面埋伏、大快朵颐等。可是,游戏引擎中实践的动作空间是这样的(动作类型 + 动作参数):
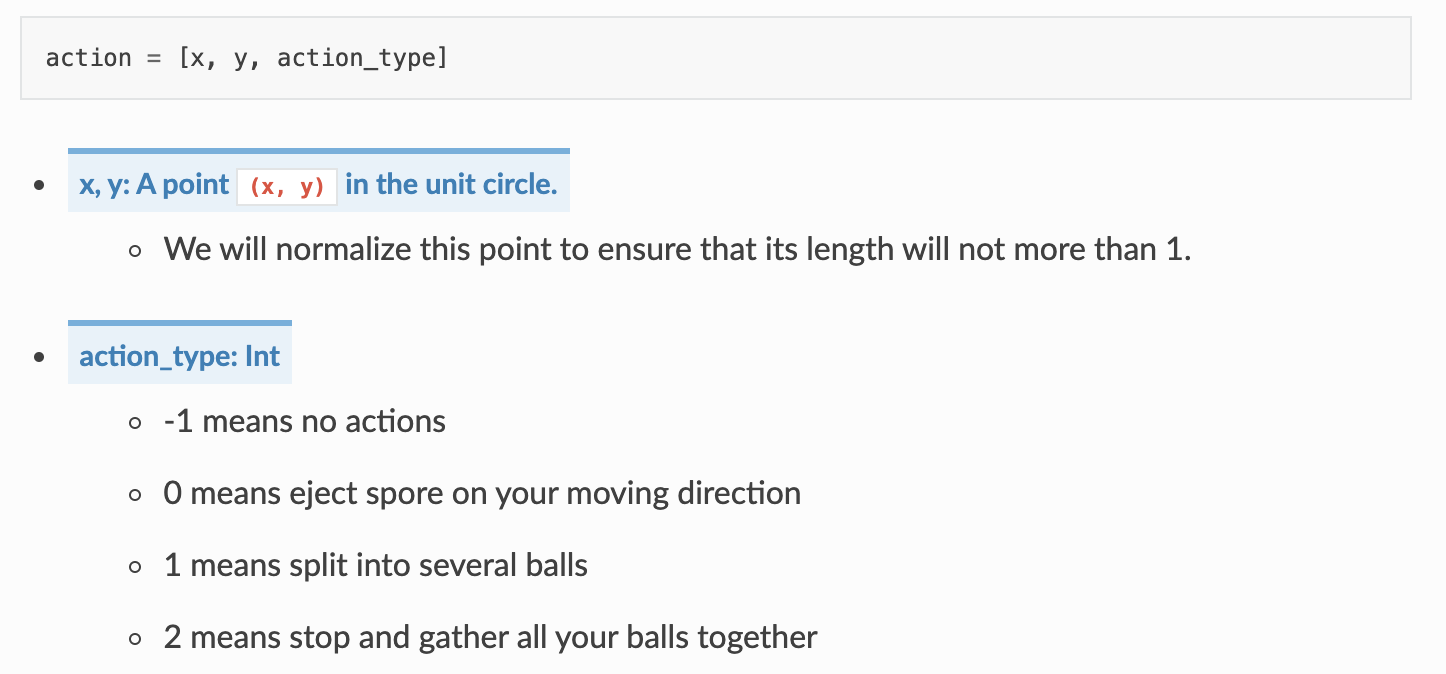
游戏引擎的这种方法在强化学习中被称作混合动作空间,也有相应的算法来处理该问题。但根据baseline全部从简这一中心,经过运用比较简略粗犷的离散化处理,将接连的动作参数(x,y坐标)离散化为上下左右四个方向。针对动作类型和动作参数的组合,也简略运用二者的笛卡尔积来表明,终究将环境界说为一个16维的离散动作空间。
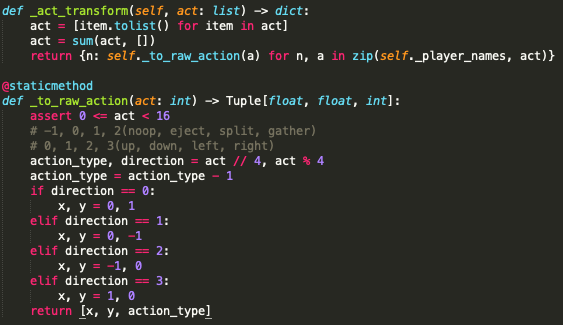
- 规划奖赏函数
奖赏函数界说了强化学习优化的方针方向。Go-Bigger是一项关于比谁的部队更大的对立游戏,因而奖赏函数的界说也十分简略,即相邻两帧整个部队的巨细之差。
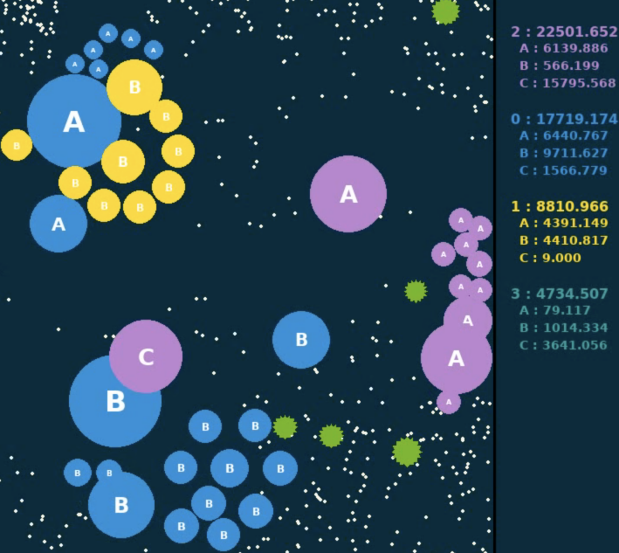
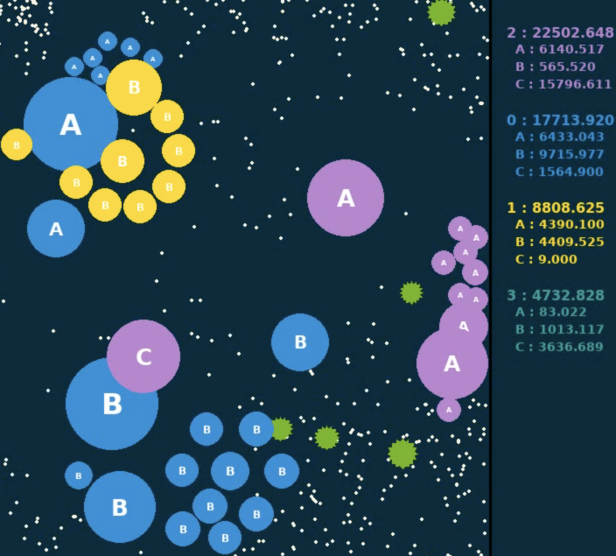
如下图所示两张表明相邻两个动作帧,右侧计分板显现各个部队实时的巨细数值,将当时帧的巨细减去上一帧的巨细,就界说得到了奖赏值。而关于整场竞赛,则运用每一步奖赏的累加和作为终究的评价值。评价值最大的部队,将赢得本局竞赛。此外,在练习时,还经过缩放和切断等手法将奖赏值约束在[-1, 1]规模内。
- 根底算法挑选
在完结对RL环境的魔改之后,会出现如下根本信息:
- 多模态调查空间:图画信息 + 单位特点信息 + 大局信息
- 离散动作空间:16维离散动作
- 奖赏函数:稠密的奖赏函数,且取值现已处理到[-1, 1]
- 停止状况:并无真实意义上的停止状况,仅约束竞赛的最长时刻
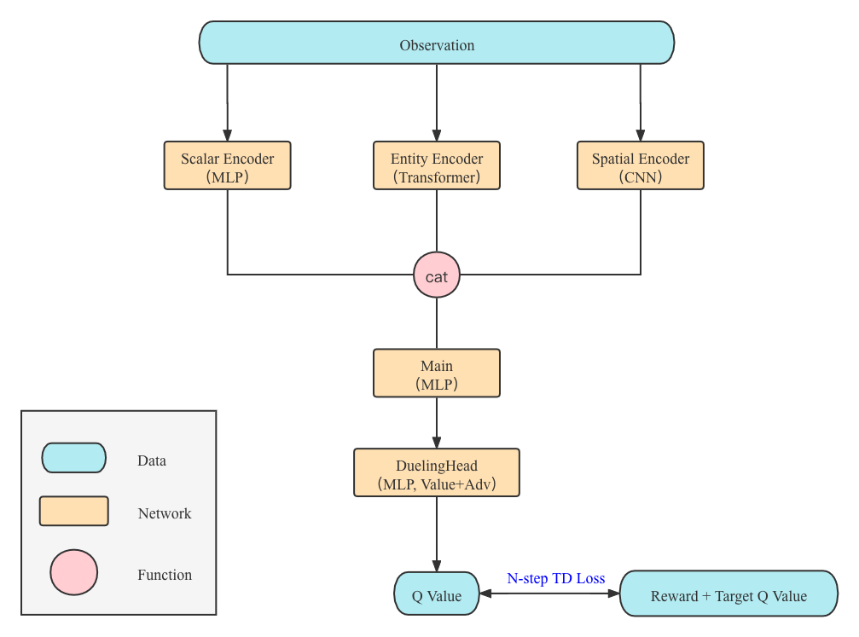
关于这样的环境,可用最经典的DQN算法 + 多模态编码器神经网络来完结。关于各种模态的调查信息,运用数据对应的经典神经网络架构即可。例如,关于图画信息,挑选一个带降采样的卷积神经网络将2D图画编码为特征向量;关于单位特点信息,需求建模各个单位之间的联络,取得终究的单位特征向量;关于大局信息,则运用由全衔接层构成的多层感知机。在各部分编码完结之后,将三部分的特征拼接在一起,将构成时刻步的调查特征向量,以复用最经典的Dueling DQN结构。以特征向量为输入,输出这一步挑选16个动作的Q值,并运用N-step TD丢失函数即可完结相应练习的优化。完好的神经网络结构如下图所示。

- 定制练习流程
DQN一般只用来处理单智能体的问题,而在Go-Bigger中一支部队会存在多个玩家,且一局竞赛为多个部队混战,因而会触及多智能体之间合作和对立等问题。在多智能体强化学习范畴,针对该问题可打开许多的研讨方向,但为简化规划Go-Bigger运用了Independent Q-Learning (IQL)+ 自我对战(Self-Play)的方法来完结练习流程。
例如,关于一个部队中的多个智能体,团队的终究方针是让整个部队(整体积/整体量/总分量)的巨细最大,因而在baseline中可运用IQL算法来完结,以高度并行化地完结整个优化进程;关于实践一局竞赛中存在多个智能体的状况,则可运用朴素的自我对战(Self-Play)这一适当简略且十分节约算力的方法来参与竞赛。评测时,会将随机机器人和根据规矩的机器人作为竞赛的对手,测验验证现在智能体的功能。
Tips:
- 运用更高档的自我对战(Self-Play)算法(比方保存智能体的中心前史版别,或运用PFSP算法);
- 构建League Training流程,不同部队运用不同的战略,不断进化博弈;
- 规划根据规矩的辅佐机器人参与到练习中,协助智能体发现缺点,学习新技能,可作为预练习的标签或League Training中的对手,也可结构蒸馏练习方法的教师,请玩家纵情脑洞。
从零开端完结上述算法和练习流程十分杂乱,而经过决议计划智能结构DI-engine(
https://github.com/opendilab/DI-engine
)可大大简化相应内容。其内部现已集成了支撑多智能体的DQN算法完结和一系列相关窍门,以及玩家自我对战和对立机器人的练习组件,只需完结相应的环境封装,神经网络模型和练习主函数即可(具体代码参阅https://github.com/opendilab/GoBigger-Challenge-2021/tree/main/di_baseline
)。几个有意思的发现
经过上述简略基线算法练习出来的初级AI在在发育阶段会将球尽量分隔,以增大接触面加速发育;在面临潜在的风险时,会避开比本身大的球,并运用割裂技能加速移动速度,避免被吃掉。这些操作都是在人类玩家的游戏进程中常常用到的小技巧。
为了进一步推进决议计划智能相关范畴的技能人才培养,打造全球抢先的原创决议计划AI开源技能生态,OpenDILab(开源决议计划智能渠道)将建议首届Go-Bigger多智能体决议计划AI应战赛(Go-Bigger: Multi-Agent Decision Intelligence Challenge)。本次竞赛将于2021年11月正式发动,运用由OpenDILab开源的Go-Bigger(
https://github.com/opendilab/GoBigger
)游戏环境。期望集结全球技能开发者和在校学生,一起探究多智能体博弈的研讨。欢迎对AI技能抱有浓厚兴趣的选手积极参与,和全球的顶尖高手一决胜负!